|
|
|
Master Student at Fudan University, Shanghai, China I am interested in Deep Learning, with a special focus on Computer Vision and Autonomouc Driving. My latest works focus on Efficient Transformer Theory and Vision-based 3D representation learning. I received B.Eng. degree in electronic and computer engineering from University of Michigan-Shanghai Jiaotong University (UM-SJTU) Joint Institute. I am now a Master student in School of Data Science, Fudan University. During my Master, I conduct my research at Zhang-vsion Group under the supervision of Prof. Li Zhang. CV / Google Scholar / LinkedIn / Email to: victor/dot/lu/dot/9901/at/gmail/dot/com |

|
|
|
I have my interest in computervision. I have worked on semantic segmentation, Transformer, efficient Transformer, vision-based 3D detection, Bird's Eye View road segmentation. |

|
Generating multi-camera street-view videos is critical for augmenting autonomous driving datasets, addressing the urgent demand for extensive and varied data. Due to the limitations in diversity and challenges in handling lighting conditions, traditional rendering-based methods are increasingly being supplanted by diffusion-based methods. However, a significant challenge in diffusion-based methods is ensuring that the generated sensor data preserve both intra-world consistency and inter-sensor coherence. To address these challenges, we combine an additional explicit world volume and propose the World Volume-aware Multi-camera Driving Scene Generator (WoVoGen). ...... |
|
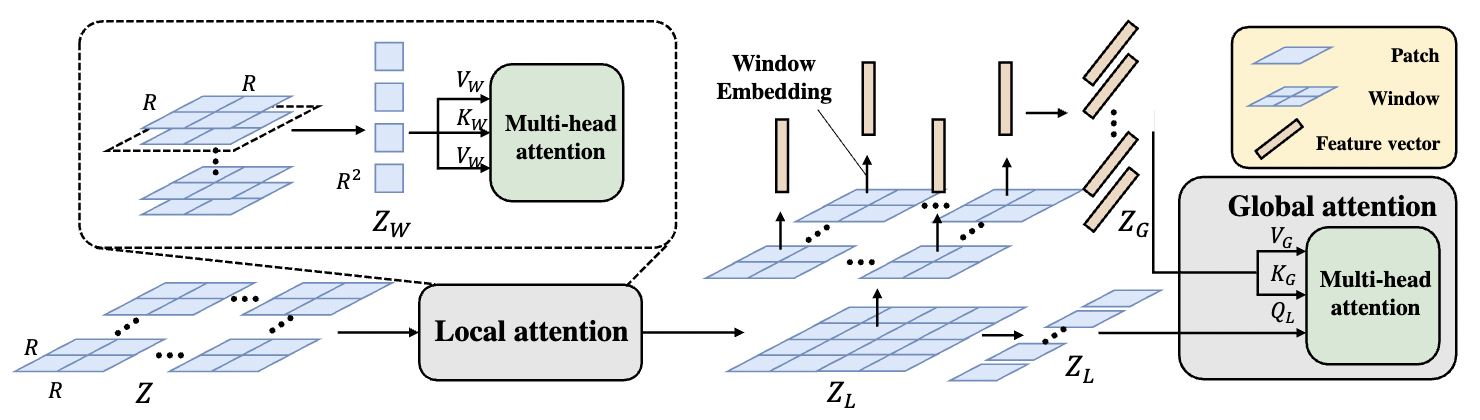
... However, the basic ViT architecture falls short in broader dense prediction applications, such as object detection and instance segmentation, due to its lack of a pyramidal structure, high computational demand, and insufficient local context. For tackling general dense visual prediction tasks in a cost-effective manner, we further formulate a family of Hierarchical Local-Global (HLG) Transformers, characterized by local attention within windows and global-attention across windows in a pyramidal architecture. Extensive experiments show that our methods achieve appealing performance on a variety of dense prediction tasks (e.g., object detection and instance segmentation and semantic segmentation) as well as image classification. |
|
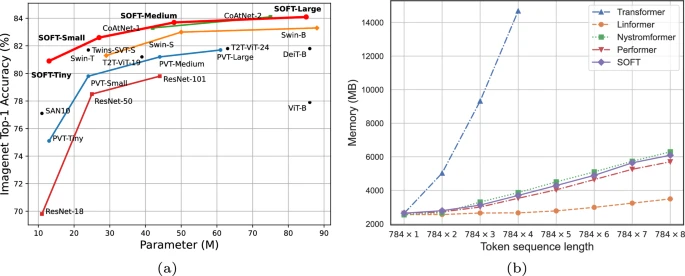
Vision transformers (ViTs) have pushed the state-of-the-art for visual perception tasks. The self-attention mechanism underpinning the strength of ViTs has a quadratic complexity in both computation and memory usage. This motivates the development of approximating the self-attention at linear complexity. However, an in-depth analysis in this work reveals that existing methods are either theoretically flawed or empirically ineffective for visual recognition. We identify that their limitations are rooted in the inheritance of softmax based self-attention during approximations, that is, normalizing the scaled dot-product between token feature vectors using the softmax function. ...... |

|
Leveraging large language models (LLMs), autonomous agents have significantly improved, gaining the ability to handle a variety of tasks. In open-ended settings, optimizing collaboration for efficiency and effectiveness demands flexible adjustments. Despite this, current research mainly emphasizes fixed, task-oriented workflows and overlooks agent-centric organizational structures. Drawing inspiration from human organizational behavior, we introduce a self-organizing agent system (S-Agents) with a "tree of agents" structure for dynamic workflow, an "hourglass agent architecture" for balancing information priorities, and a "non-obstructive collaboration" method to allow asynchronous task execution among agents. ...... |

|
High-resolution 3D object generation remains a challenging task primarily due to the limited availability of comprehensive annotated training data. Recent advancements have aimed to overcome this constraint by harnessing image generative models, pretrained on extensive curated web datasets, using knowledge transfer techniques like Score Distillation Sampling (SDS). Efficiently addressing the requirements of high-resolution rendering often necessitates the adoption of latent representation-based models, such as the Latent Diffusion Model (LDM). In this framework, a significant challenge arises: To compute gradients for individual image pixels, it is necessary to backpropagate gradients from the designated latent space through the frozen components of the image model, such as the VAE encoder used within LDM. However, this gradient propagation pathway has never been optimized, remaining uncontrolled during training. We find that the unregulated gradients adversely affect the 3D model's capacity in acquiring texture-related information from the image generative model, leading to poor quality appearance synthesis. ...... |
|
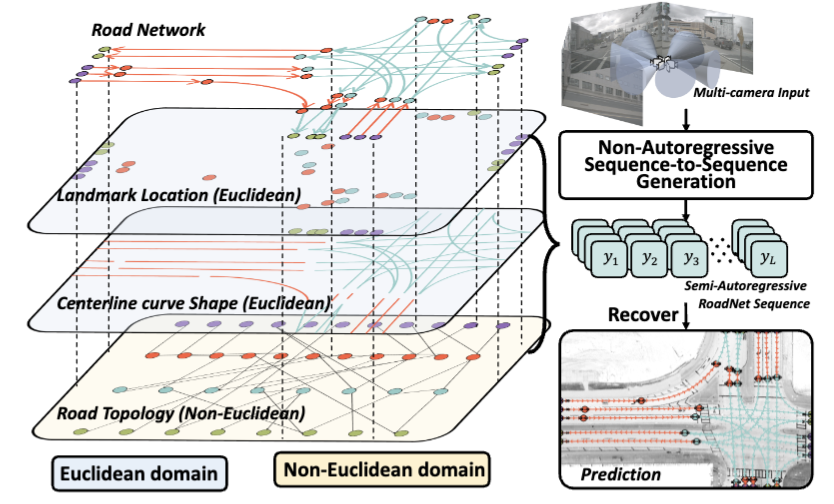
The extraction of road network is essential for the generation of high-definition maps since it enables the precise localization of road landmarks and their interconnections. However, generating road network poses a significant challenge due to the conflicting underlying combination of Euclidean (eg, road landmarks location) and non-Euclidean (eg, road topological connectivity) structures. Existing methods struggle to merge the two types of data domains effectively, but few of them address it properly. Instead, our work establishes a unified representation of both types of data domain by projecting both Euclidean and non-Euclidean data into an integer series called RoadNet Sequence. ...... |
|
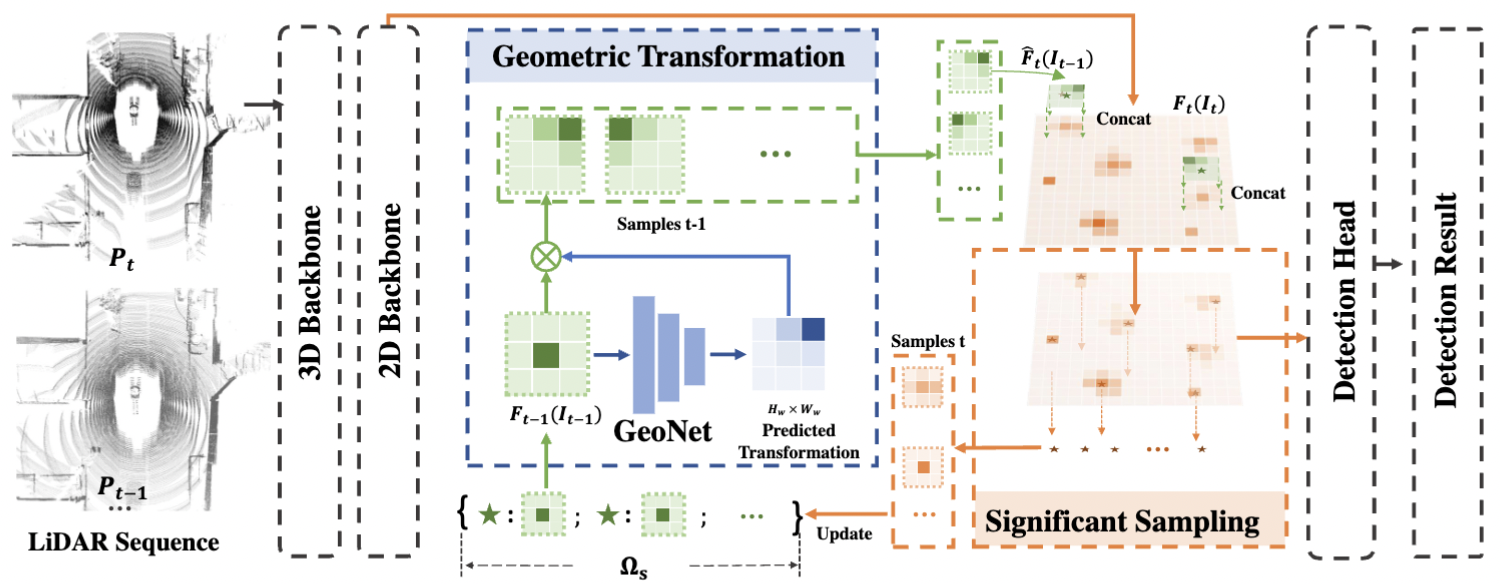
3D object detection from LiDAR point cloud is of critical importance for autonomous driving and robotics. While sequential point cloud has the potential to enhance 3D perception through temporal information, utilizing these temporal features effectively and efficiently remains a challenging problem. Based on the observation that the foreground information is sparsely distributed in LiDAR scenes, we believe sufficient knowledge can be provided by sparse format rather than dense maps. To this end, we propose to learn Significance-gUided Information for 3D Temporal detection (SUIT), which simplifies temporal information as sparse features for information fusion across frames. ...... |
|
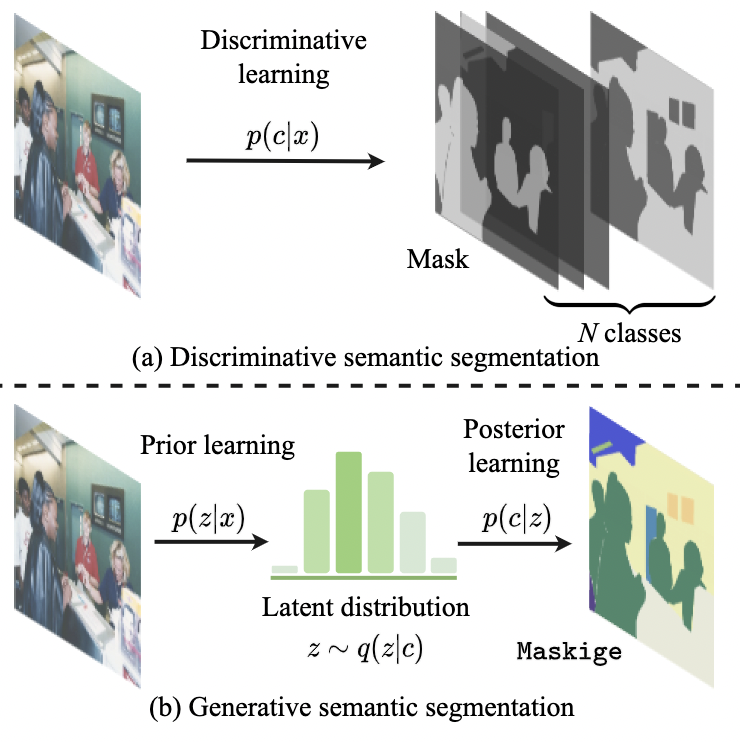
We present Generative Semantic Segmentation (GSS), a generative learning approach for semantic segmentation. Uniquely, we cast semantic segmentation as an image-conditioned mask generation problem. This is achieved by replacing the conventional per-pixel discriminative learning with a latent prior learning process. Specifically, we model the variational posterior distribution of latent variables given the segmentation mask. To that end, the segmentation mask is expressed with a special type of image (dubbed as maskige). This posterior distribution allows to generate segmentation masks unconditionally. To achieve semantic segmentation on a given image, we further introduce a conditioning network. It is optimized by minimizing the divergence between the posterior distribution of maskige (i.e., segmentation masks) and the latent prior distribution of input training images. Extensive experiments on standard benchmarks show that our GSS can perform competitively to prior art alternatives in the standard semantic segmentation setting, whilst achieving a new state of the art in the more challenging cross-domain setting. |
|
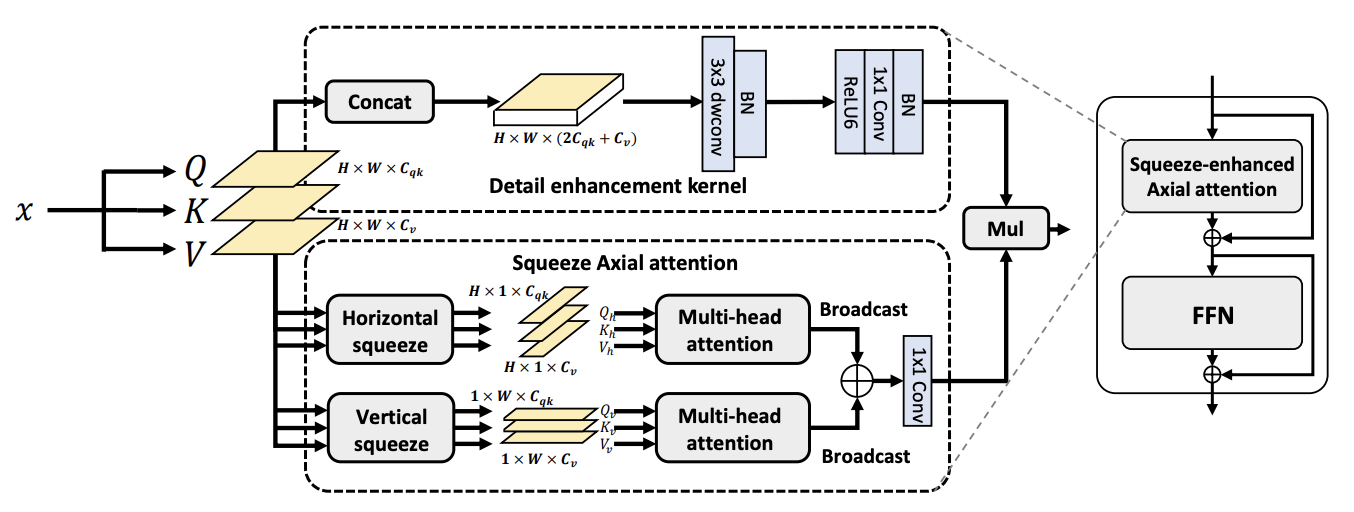
Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement render these methods unsuitable on the mobile device, especially for the high resolution per-pixel semantic segmentation task. In this paper, we introduce a new method squeeze-enhanced Axial Transformer (SeaFormer) for mobile semantic segmentation. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and spatial enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. ...... |
|
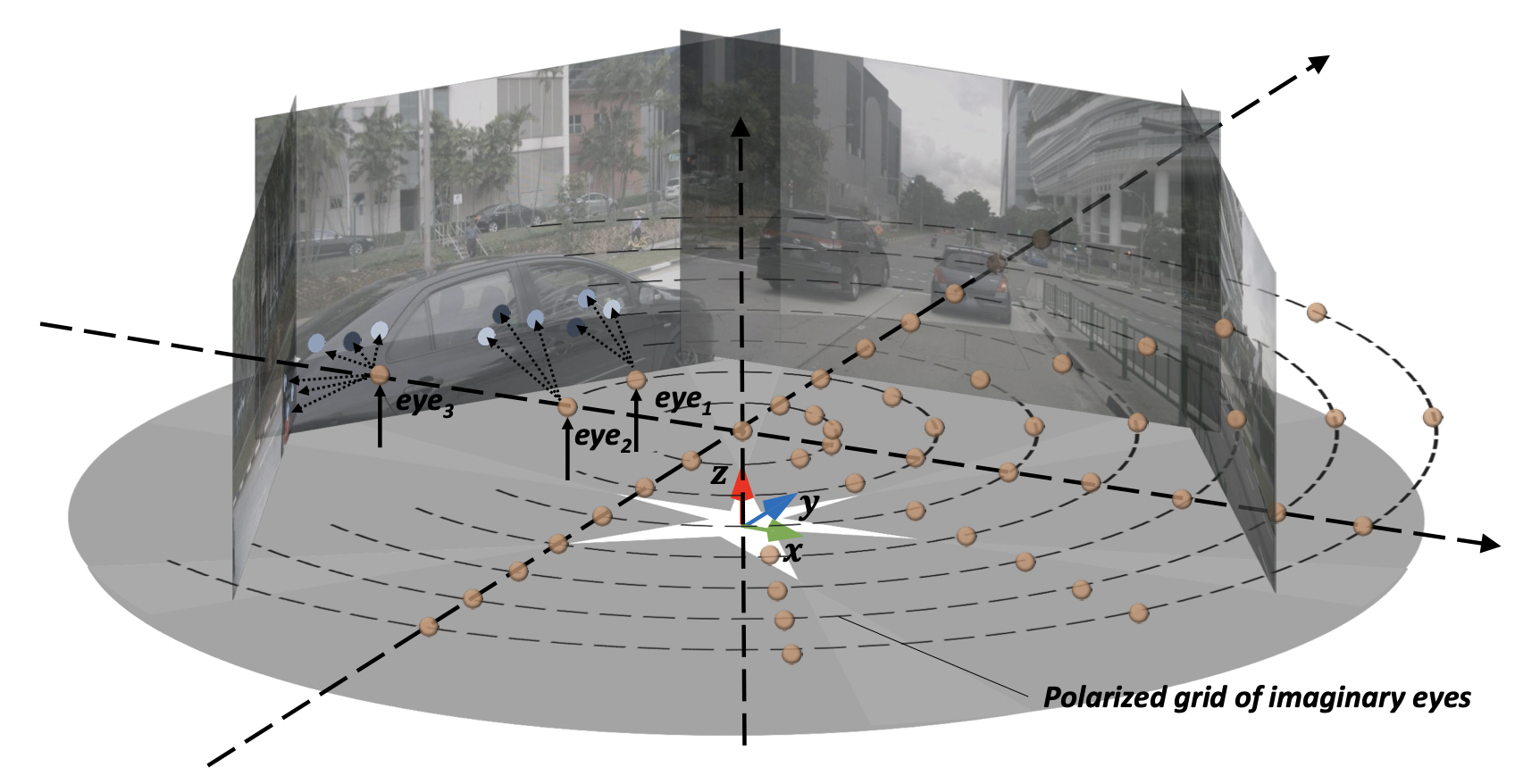
A self-driving perception model aims to extract 3D semantic representations from multiple cameras collectively into the bird's-eye-view (BEV) coordinate frame of the ego car in order to ground downstream planner. Existing perception methods often rely on error-prone depth estimation of the whole scene or learning sparse virtual 3D representations without the target geometry structure, both of which remain limited in performance and/or capability. In this paper, we present a novel end-to-end architecture for ego 3D representation learning from an arbitrary number of unconstrained camera views. Inspired by the ray tracing principle, we design a polarized grid of "imaginary eyes" as the learnable ego 3D representation and formulate the learning process with the adaptive attention mechanism in conjunction with the 3D-to-2D projection. ...... |

|
Vision transformers (ViTs) have pushed the state-of-the-art for various visual recognition tasks by patch-wise image tokenization followed by self-attention. However, the employment of self-attention modules results in a quadratic complexity in both computation and memory usage. Various attempts on approximating the self-attention computation with linear complexity have been made in Natural Language Processing. However, an in-depth analysis in this work shows that they are either theoretically flawed or empirically ineffective for visual recognition. We further identify that their limitations are rooted in keeping the softmax self-attention during approximations. Specifically, conventional self-attention is computed by normalizing the scaled dot-product between token feature vectors. Keeping this softmax operation challenges any subsequent linearization efforts. ...... |
|
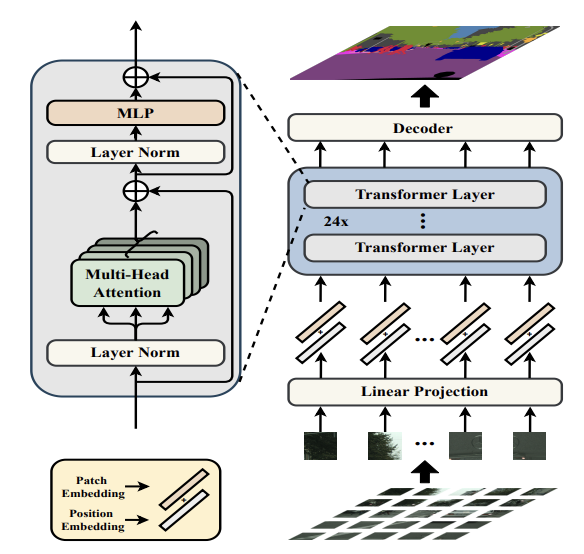
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission. |
|
|
|