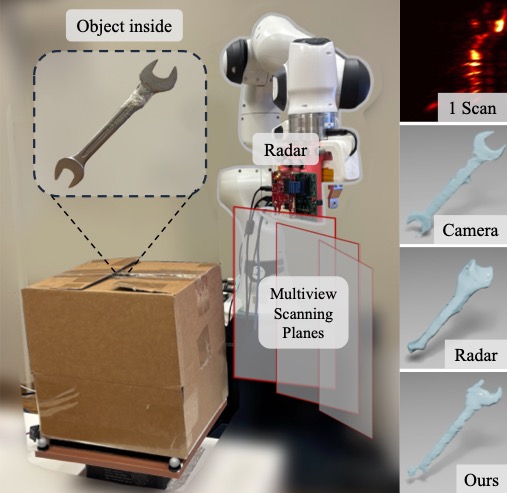
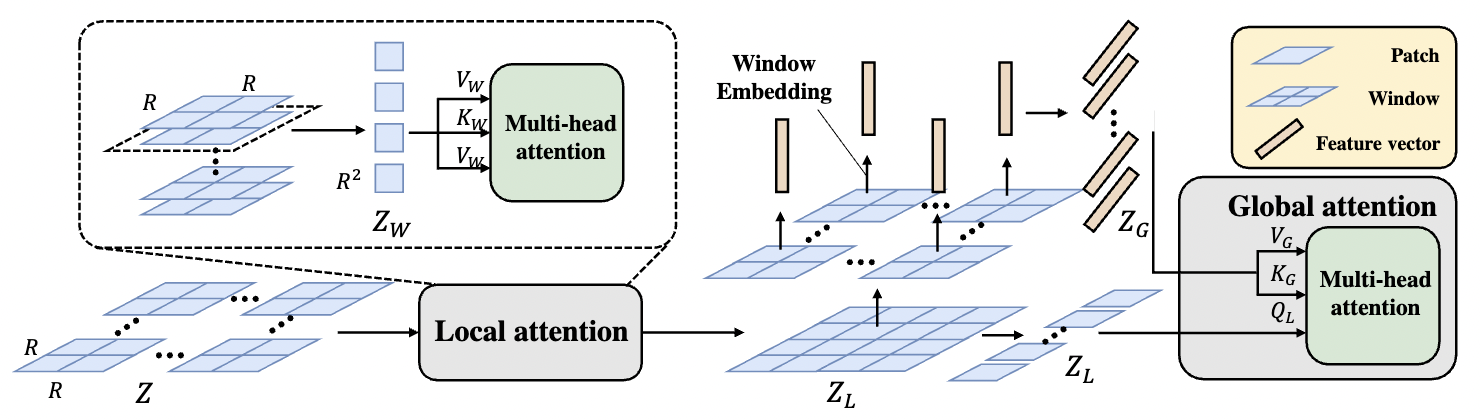
@inproceedings{lu2025geraf,title={GeRaF: Neural Geometry Reconstruction from Radio Frequency Signals},author={Lu, Jiachen and Shanbhag, Hailan and Al Hassanieh, Haitham},booktitle={Conference on Neural Information Processing Systems (NeurIPS)},year={2025},}
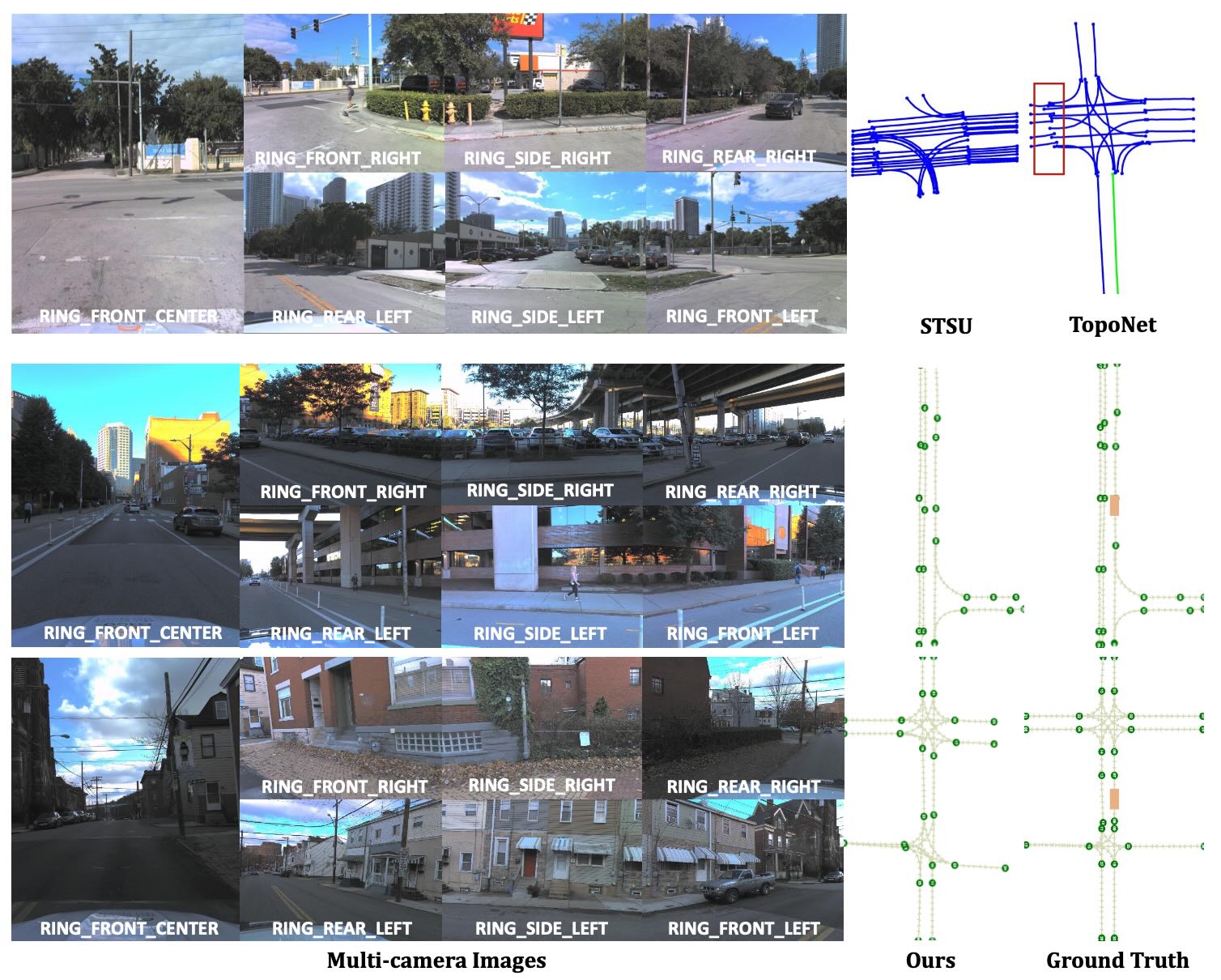
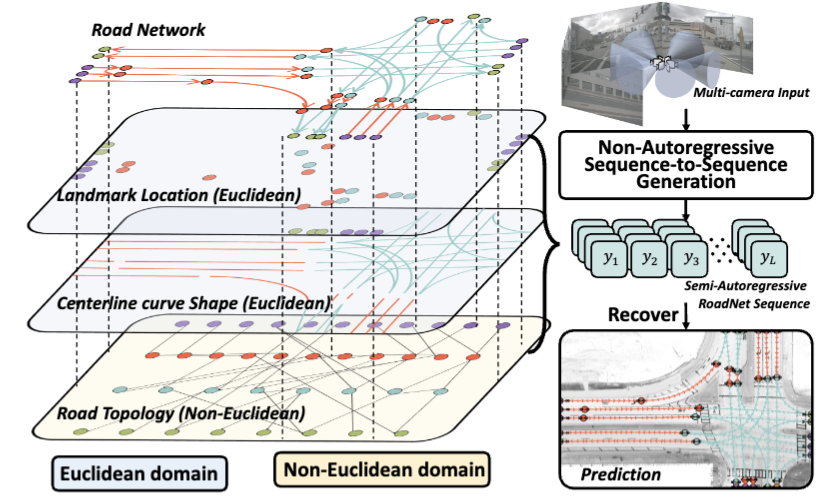
Translating Images to Road Network: A Sequence-to-Sequence Perspective
Jiachen Lu, Ming Nie, Bozhou Zhang, Renyuan Peng, Xinyue Cai, Hang Xu, Feng Wen, Wei Zhang, and Li Zhang
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
@article{lu2025translating,title={Translating Images to Road Network: A Sequence-to-Sequence Perspective},author={Lu, Jiachen and Nie, Ming and Zhang, Bozhou and Peng, Renyuan and Cai, Xinyue and Xu, Hang and Wen, Feng and Zhang, Wei and Zhang, Li},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},year={2025},publisher={IEEE},doi={10.1109/TPAMI.2025.3612940},}
SeaFormer++: Squeeze-enhanced axial transformer for mobile visual recognition
Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, and Li Zhang
International Journal of Computer Vision (IJCV), 2025
@article{wan2025seaformer++,title={SeaFormer++: Squeeze-enhanced axial transformer for mobile visual recognition},author={Wan, Qiang and Huang, Zilong and Lu, Jiachen and Yu, Gang and Zhang, Li},journal={International Journal of Computer Vision (IJCV)},volume={133},number={6},pages={3645--3666},year={2025},publisher={Springer},doi={10.1007/s11263-025-02345-2},}
S-nerf++: Autonomous driving simulation via neural reconstruction and generation
Yurui Chen, Junge Zhang, Ziyang Xie, Wenye Li, Feihu Zhang, Jiachen Lu, and Li Zhang
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
@article{chen2025s,title={S-nerf++: Autonomous driving simulation via neural reconstruction and generation},author={Chen, Yurui and Zhang, Junge and Xie, Ziyang and Li, Wenye and Zhang, Feihu and Lu, Jiachen and Zhang, Li},journal={IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},year={2025},publisher={IEEE},doi={10.1109/TPAMI.2025.3543072},}
2024
Vision transformers: From semantic segmentation to dense prediction
Li Zhang, Jiachen Lu, Sixiao Zheng, Xinxuan Zhao, Xiatian Zhu, Yanwei Fu, Tao Xiang, Jianfeng Feng, and Philip HS Torr
International Journal of Computer Vision (IJCV), 2024
@article{zhang2024vision,title={Vision transformers: From semantic segmentation to dense prediction},author={Zhang, Li and Lu, Jiachen and Zheng, Sixiao and Zhao, Xinxuan and Zhu, Xiatian and Fu, Yanwei and Xiang, Tao and Feng, Jianfeng and Torr, Philip HS},journal={International Journal of Computer Vision (IJCV)},volume={132},number={12},pages={6142--6162},year={2024},publisher={Springer},doi={10.1007/s11263-024-02173-w}}
Wovogen: World volume-aware diffusion for controllable multi-camera driving scene generation
Jiachen Lu, Ze Huang, Zeyu Yang, Jiahui Zhang, and Li Zhang
In European Conference on Computer Vision (ECCV), 2024
@inproceedings{lu2024wovogen,title={Wovogen: World volume-aware diffusion for controllable multi-camera driving scene generation},author={Lu, Jiachen and Huang, Ze and Yang, Zeyu and Zhang, Jiahui and Zhang, Li},booktitle={European Conference on Computer Vision (ECCV)},pages={329--345},year={2024},organization={Springer},}
Lanegraph2seq: Lane topology extraction with language model via vertex-edge encoding and connectivity enhancement
Renyuan Peng, Xinyue Cai, Hang Xu, Jiachen Lu, Feng Wen, Wei Zhang, and Li Zhang
In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024
@inproceedings{peng2024lanegraph2seq,title={Lanegraph2seq: Lane topology extraction with language model via vertex-edge encoding and connectivity enhancement},author={Peng, Renyuan and Cai, Xinyue and Xu, Hang and Lu, Jiachen and Wen, Feng and Zhang, Wei and Zhang, Li},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},volume={38},number={5},pages={4497--4505},year={2024},}
Softmax-free linear transformers
Jiachen Lu, Junge Zhang, Xiatian Zhu, Jianfeng Feng, Tao Xiang, and Li Zhang
International Journal of Computer Vision (IJCV), 2024
@article{lu2024softmax,title={Softmax-free linear transformers},author={Lu, Jiachen and Zhang, Junge and Zhu, Xiatian and Feng, Jianfeng and Xiang, Tao and Zhang, Li},journal={International Journal of Computer Vision (IJCV)},volume={132},number={8},pages={3355--3374},year={2024},publisher={Springer},doi={10.1007/s11263-024-02035-5}}
Enhancing High-Resolution 3D Generation through Pixel-wise Gradient Clipping
Zijie Pan, Jiachen Lu, Xiatian Zhu, and Li Zhang
In The Twelfth International Conference on Learning Representations (ICLR), 2024
@inproceedings{pan2023enhancing,author={Pan, Zijie and Lu, Jiachen and Zhu, Xiatian and Zhang, Li},title={Enhancing High-Resolution 3D Generation through Pixel-wise Gradient
Clipping},booktitle={The Twelfth International Conference on Learning Representations (ICLR)},year={2024},}
2023
Translating images to road network: A non-autoregressive sequence-to-sequence approach
Jiachen Lu, Renyuan Peng, Xinyue Cai, Hang Xu, Hongyang Li, Feng Wen, Wei Zhang, and Li Zhang
In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
@inproceedings{lu2023translating,selected=true,title={Translating images to road network: A non-autoregressive sequence-to-sequence approach},author={Lu, Jiachen and Peng, Renyuan and Cai, Xinyue and Xu, Hang and Li, Hongyang and Wen, Feng and Zhang, Wei and Zhang, Li},booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},pages={23--33},year={2023},}
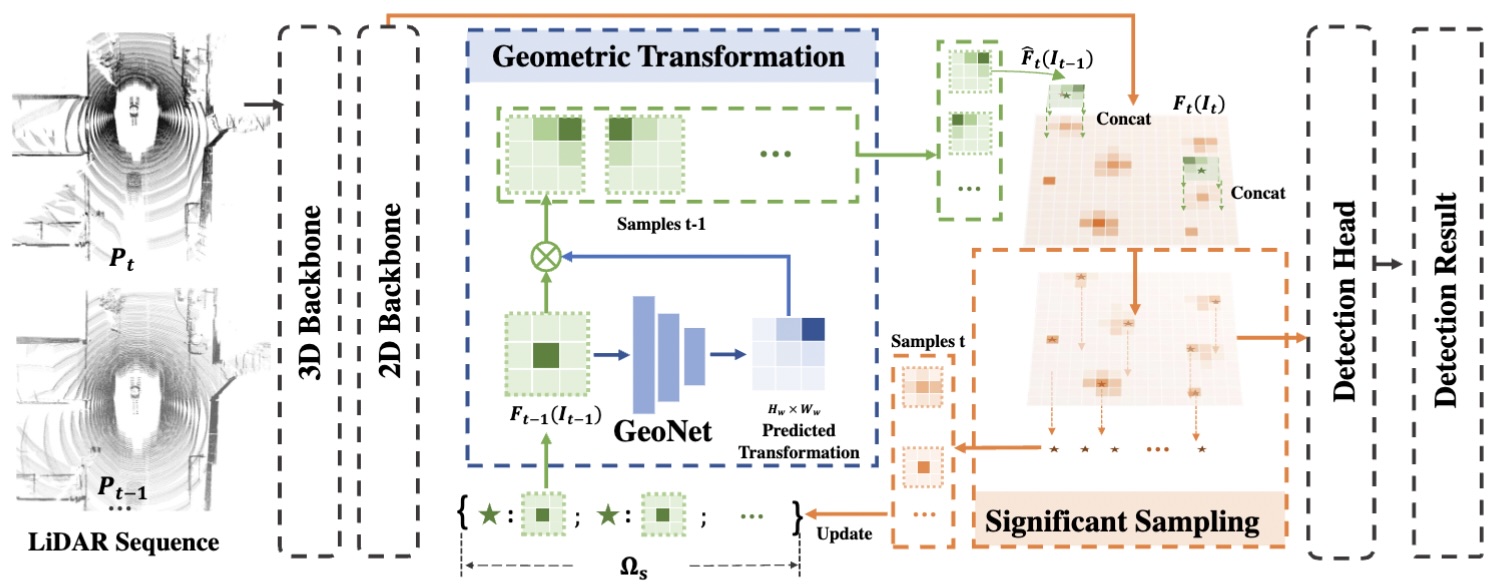
Suit: Learning significance-guided information for 3d temporal detection
Zheyuan Zhou, Jiachen Lu, Yihan Zeng, Hang Xu, and Li Zhang
In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
@inproceedings{zhou2023suit,title={Suit: Learning significance-guided information for 3d temporal detection},author={Zhou, Zheyuan and Lu, Jiachen and Zeng, Yihan and Xu, Hang and Zhang, Li},booktitle={2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},pages={9399--9406},year={2023},organization={IEEE},}
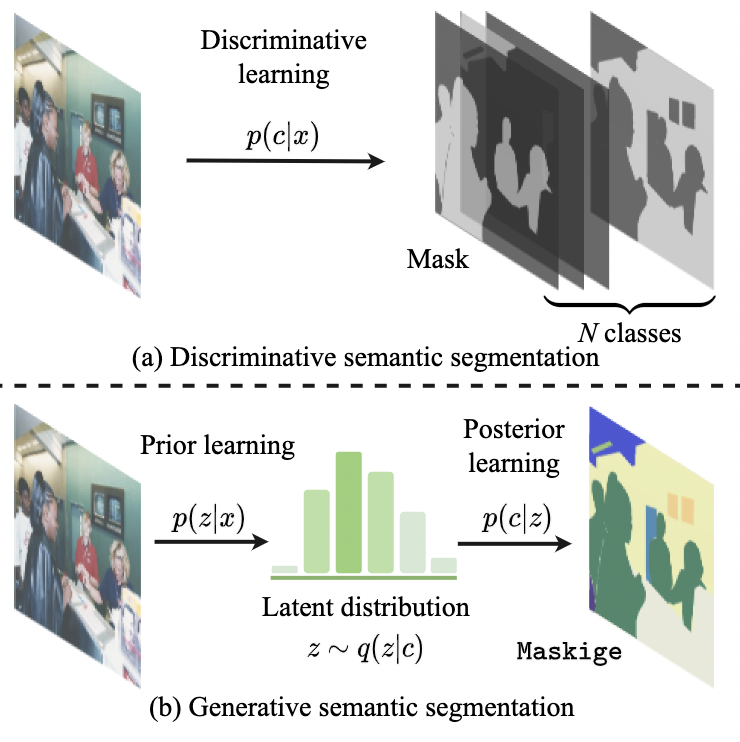
Generative semantic segmentation
Jiaqi Chen, Jiachen Lu, Xiatian Zhu, and Li Zhang
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2023
@inproceedings{chen2023generative,title={Generative semantic segmentation},author={Chen, Jiaqi and Lu, Jiachen and Zhu, Xiatian and Zhang, Li},booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)},pages={7111--7120},year={2023},}
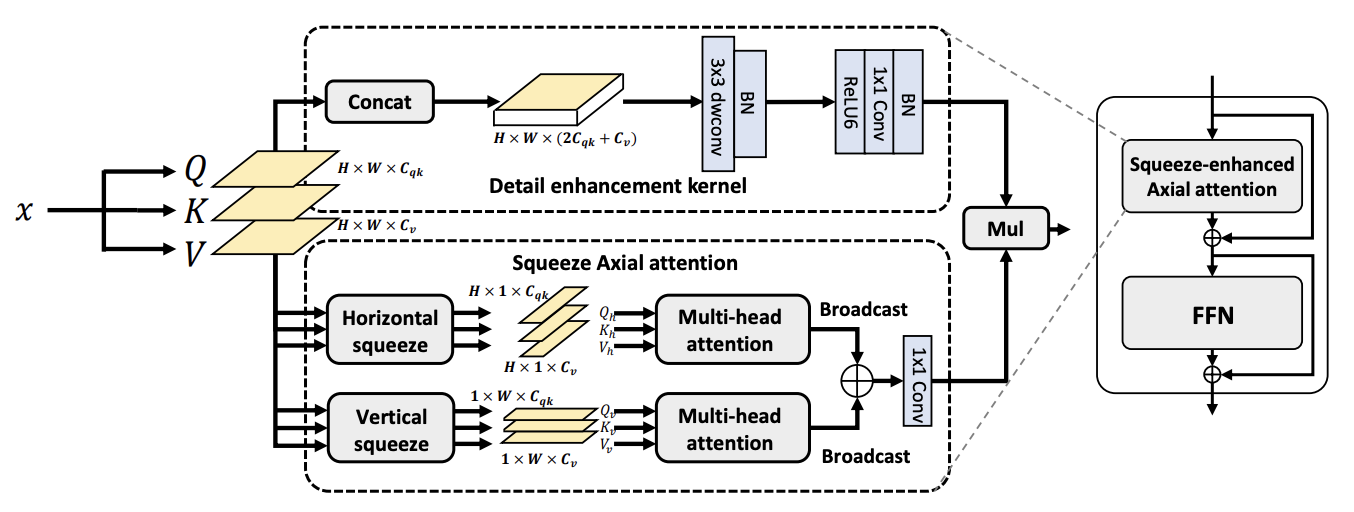
Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation
Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, and Li Zhang
In The eleventh international conference on learning representations (ICLR), 2023
@inproceedings{wan2023seaformer,title={Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation},author={Wan, Qiang and Huang, Zilong and Lu, Jiachen and Yu, Gang and Zhang, Li},booktitle={The eleventh international conference on learning representations (ICLR)},year={2023},}
2022
Learning ego 3d representation as ray tracing
Jiachen Lu, Zheyuan Zhou, Xiatian Zhu, Hang Xu, and Li Zhang
In European conference on computer vision (ECCV), 2022
@inproceedings{lu2022learning,selected=true,title={Learning ego 3d representation as ray tracing},author={Lu, Jiachen and Zhou, Zheyuan and Zhu, Xiatian and Xu, Hang and Zhang, Li},booktitle={European conference on computer vision (ECCV)},pages={129--144},year={2022},organization={Springer},}
2021
Soft: Softmax-free transformer with linear complexity
Jiachen Lu, Jinghan Yao, Junge Zhang, Xiatian Zhu, Hang Xu, Weiguo Gao, Chunjing Xu, Tao Xiang, and Li Zhang
In Conference on Neural Information Processing Systems (NeurIPS), 2021
@inproceedings{lu2021soft,selected=true,title={Soft: Softmax-free transformer with linear complexity},author={Lu, Jiachen and Yao, Jinghan and Zhang, Junge and Zhu, Xiatian and Xu, Hang and Gao, Weiguo and Xu, Chunjing and Xiang, Tao and Zhang, Li},booktitle={Conference on Neural Information Processing Systems (NeurIPS)},year={2021},}
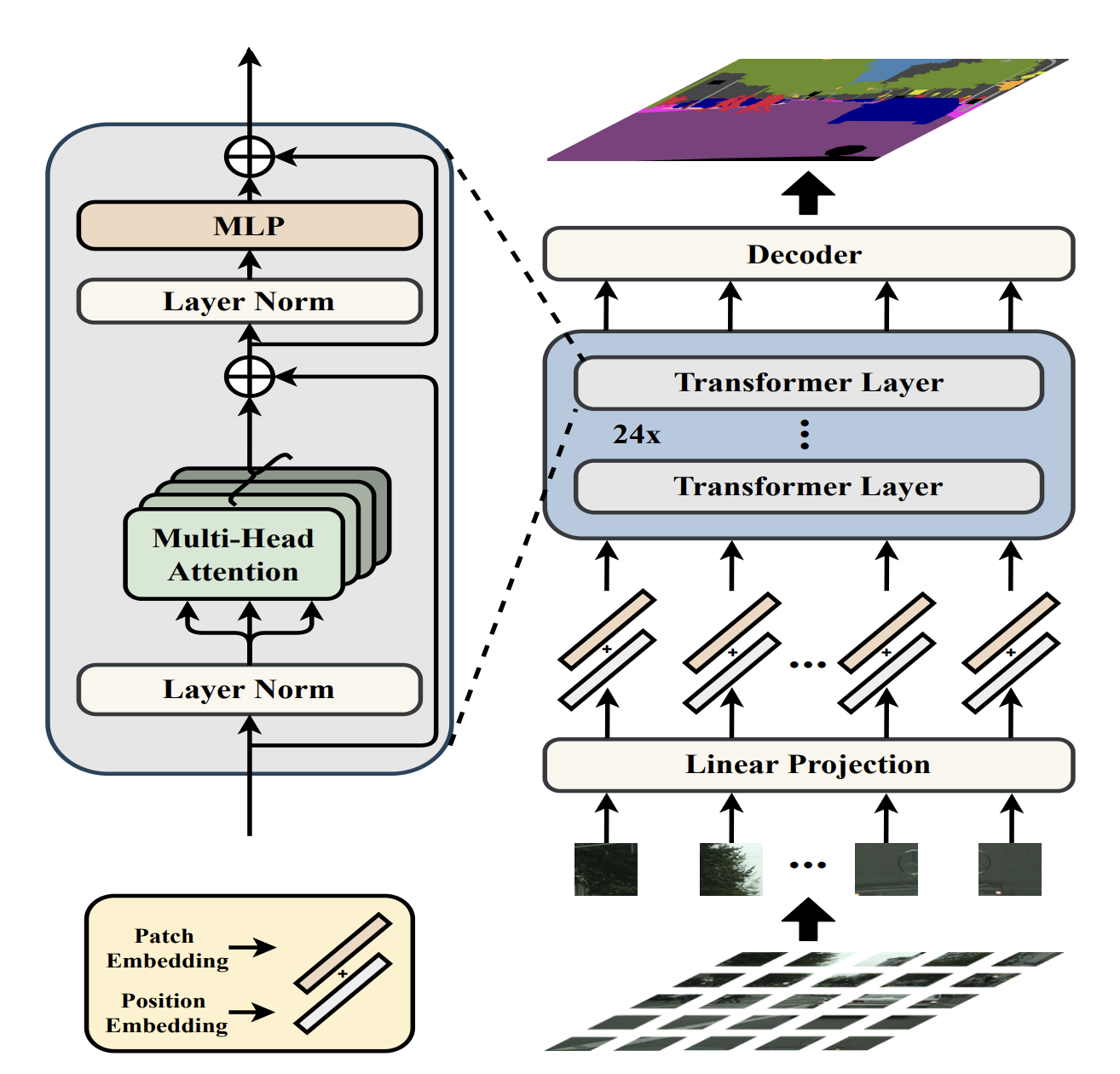
Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers
Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, and others
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2021
@inproceedings{zheng2021rethinking,selected=true,title={Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers},author={Zheng, Sixiao and Lu, Jiachen and Zhao, Hengshuang and Zhu, Xiatian and Luo, Zekun and Wang, Yabiao and Fu, Yanwei and Feng, Jianfeng and Xiang, Tao and Torr, Philip HS and others},booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)},pages={6881--6890},year={2021},}
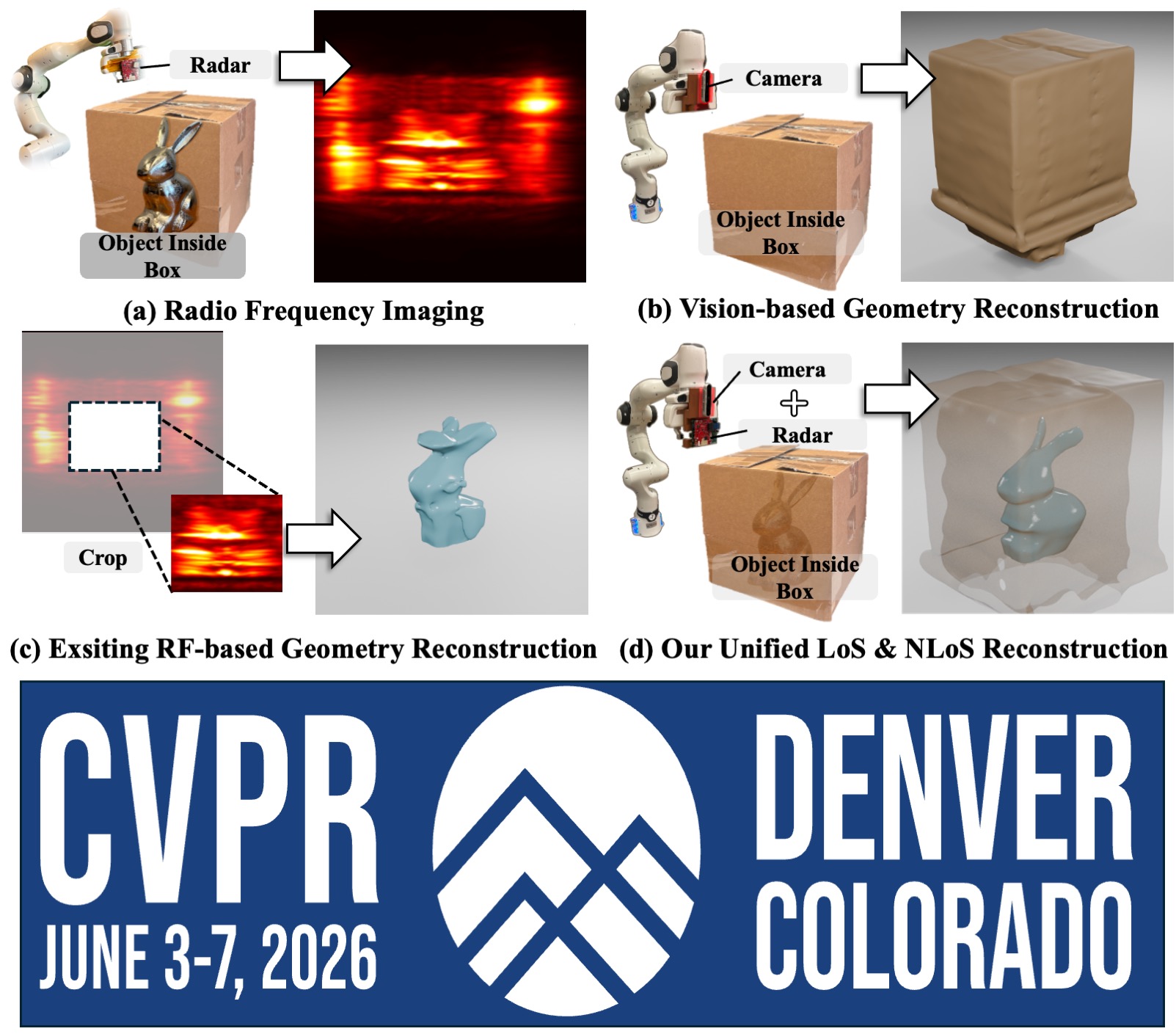 Seeing through boxes: Non-Line-of-Sight 3D Reconstruction from Radar SignalsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2026
Seeing through boxes: Non-Line-of-Sight 3D Reconstruction from Radar SignalsIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun 2026